static int __init_memblock memblock_add_range(struct memblock_type *type,
phys_addr_t base, phys_addr_t size,
int nid, enum memblock_flags flags)
{
bool insert = false;
phys_addr_t obase = base;
phys_addr_t end = base + memblock_cap_size(base, &size);
int idx, nr_new, start_rgn = -1, end_rgn;
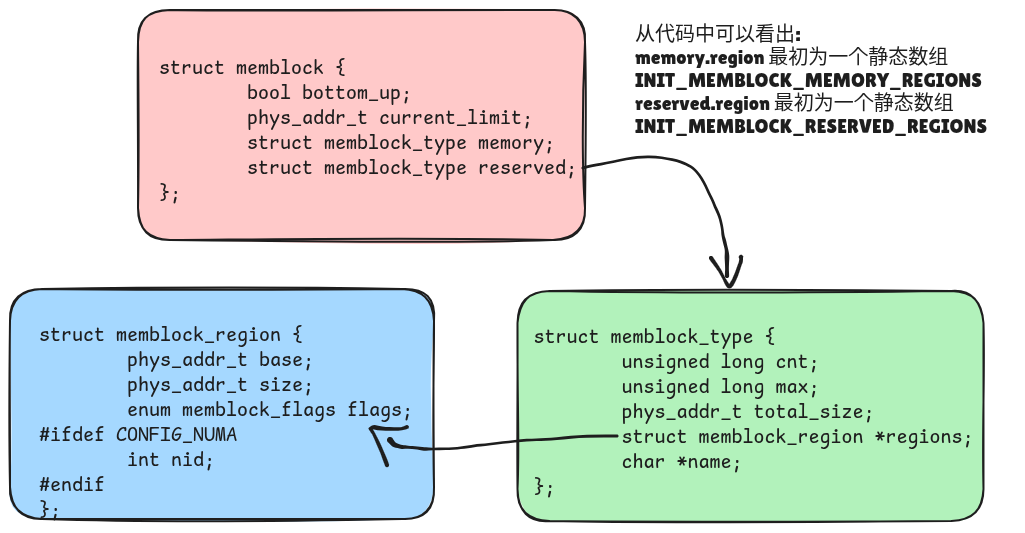
struct memblock_region *rgn;
if (!size)
return 0;
/* special case for empty array */
if (type->regions[0].size == 0) {
WARN_ON(type->cnt != 0 || type->total_size);
type->regions[0].base = base;
type->regions[0].size = size;
type->regions[0].flags = flags;
memblock_set_region_node(&type->regions[0], nid);
type->total_size = size;
type->cnt = 1;
return 0;
}
/*
* The worst case is when new range overlaps all existing regions,
* then we'll need type->cnt + 1 empty regions in @type. So if
* type->cnt * 2 + 1 is less than or equal to type->max, we know
* that there is enough empty regions in @type, and we can insert
* regions directly.
*/
if (type->cnt * 2 + 1 <= type->max)
insert = true;
repeat:
/*
* The following is executed twice. Once with %false @insert and
* then with %true. The first counts the number of regions needed
* to accommodate the new area. The second actually inserts them.
*/
base = obase;
nr_new = 0;
for_each_memblock_type(idx, type, rgn) {
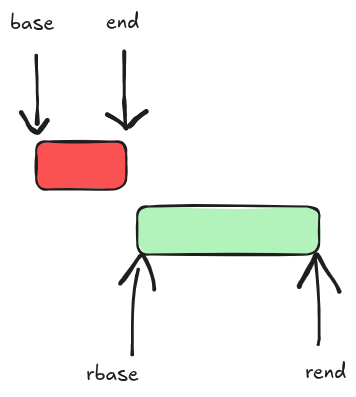
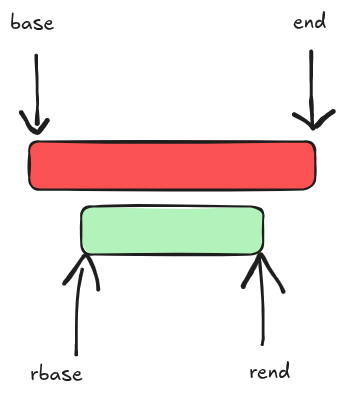
phys_addr_t rbase = rgn->base;
phys_addr_t rend = rbase + rgn->size;
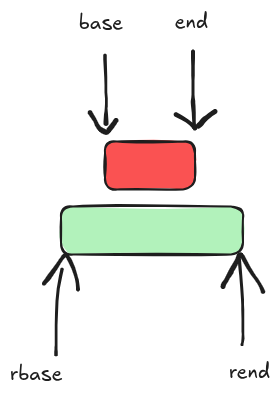
if (rbase >= end)
break;
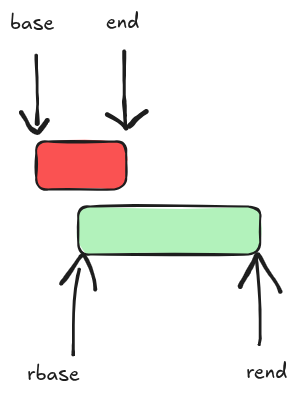
if (rend <= base)
continue;
/*
* @rgn overlaps. If it separates the lower part of new
* area, insert that portion.
*/
if (rbase > base) {
#ifdef CONFIG_NUMA
WARN_ON(nid != memblock_get_region_node(rgn));
#endif
WARN_ON(flags != MEMBLOCK_NONE && flags != rgn->flags);
nr_new++;
if (insert) {
if (start_rgn == -1)
start_rgn = idx;
end_rgn = idx + 1;
memblock_insert_region(type, idx++, base,
rbase - base, nid,
flags);
}
}
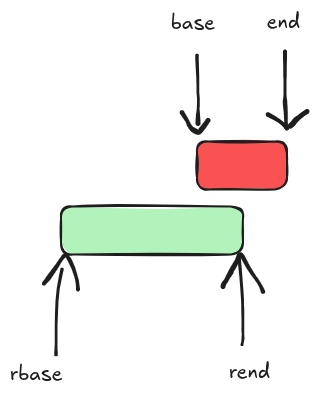
/* area below @rend is dealt with, forget about it */
base = min(rend, end);
}
bool insert = false;
phys_addr_t obase = base;
phys_addr_t end = base + memblock_cap_size(base, &size);
int idx, nr_new, start_rgn = -1, end_rgn;
struct memblock_region *rgn;
if (!size)
return 0;
/* special case for empty array */
if (type->regions[0].size == 0) {
WARN_ON(type->cnt != 0 || type->total_size);
type->regions[0].base = base;
type->regions[0].size = size;
type->regions[0].flags = flags;
memblock_set_region_node(&type->regions[0], nid);
type->total_size = size;
type->cnt = 1;
return 0;
}
/*
* The worst case is when new range overlaps all existing regions,
* then we'll need type->cnt + 1 empty regions in @type. So if
* type->cnt * 2 + 1 is less than or equal to type->max, we know
* that there is enough empty regions in @type, and we can insert
* regions directly.
*/
if (type->cnt * 2 + 1 <= type->max)
insert = true;
repeat:
/*
* The following is executed twice. Once with %false @insert and
* then with %true. The first counts the number of regions needed
* to accommodate the new area. The second actually inserts them.
*/
base = obase;
nr_new = 0;
for_each_memblock_type(idx, type, rgn) {
phys_addr_t rbase = rgn->base;
phys_addr_t rend = rbase + rgn->size;
if (rbase >= end)
break;
if (rend <= base)
continue;
/*
* @rgn overlaps. If it separates the lower part of new
* area, insert that portion.
*/
if (rbase > base) {
#ifdef CONFIG_NUMA
WARN_ON(nid != memblock_get_region_node(rgn));
#endif
WARN_ON(flags != MEMBLOCK_NONE && flags != rgn->flags);
nr_new++;
if (insert) {
if (start_rgn == -1)
start_rgn = idx;
end_rgn = idx + 1;
memblock_insert_region(type, idx++, base,
rbase - base, nid,
flags);
}
}
/* area below @rend is dealt with, forget about it */
base = min(rend, end);
}
/* insert the remaining portion */
if (base < end) {
nr_new++;
if (insert) {
if (start_rgn == -1)
start_rgn = idx;
end_rgn = idx + 1;
memblock_insert_region(type, idx, base, end - base,
nid, flags);
}
}
if (!nr_new)
return 0;
/*
* If this was the first round, resize array and repeat for actual
* insertions; otherwise, merge and return.
*/
if (!insert) {
while (type->cnt + nr_new > type->max)
if (memblock_double_array(type, obase, size) < 0)
return -ENOMEM;
insert = true;
goto repeat;
} else {
memblock_merge_regions(type, start_rgn, end_rgn);
return 0;
}
}
/* insert the remaining portion */
if (base < end) {
nr_new++;
if (insert) {
if (start_rgn == -1)
start_rgn = idx;
end_rgn = idx + 1;
memblock_insert_region(type, idx, base, end - base,
nid, flags);
}
}
if (!nr_new)
return 0;
/*
* If this was the first round, resize array and repeat for actual
* insertions; otherwise, merge and return.
*/
if (!insert) {
while (type->cnt + nr_new > type->max)
if (memblock_double_array(type, obase, size) < 0)
return -ENOMEM;
insert = true;
goto repeat;
} else {
memblock_merge_regions(type, start_rgn, end_rgn);
return 0;
}
}
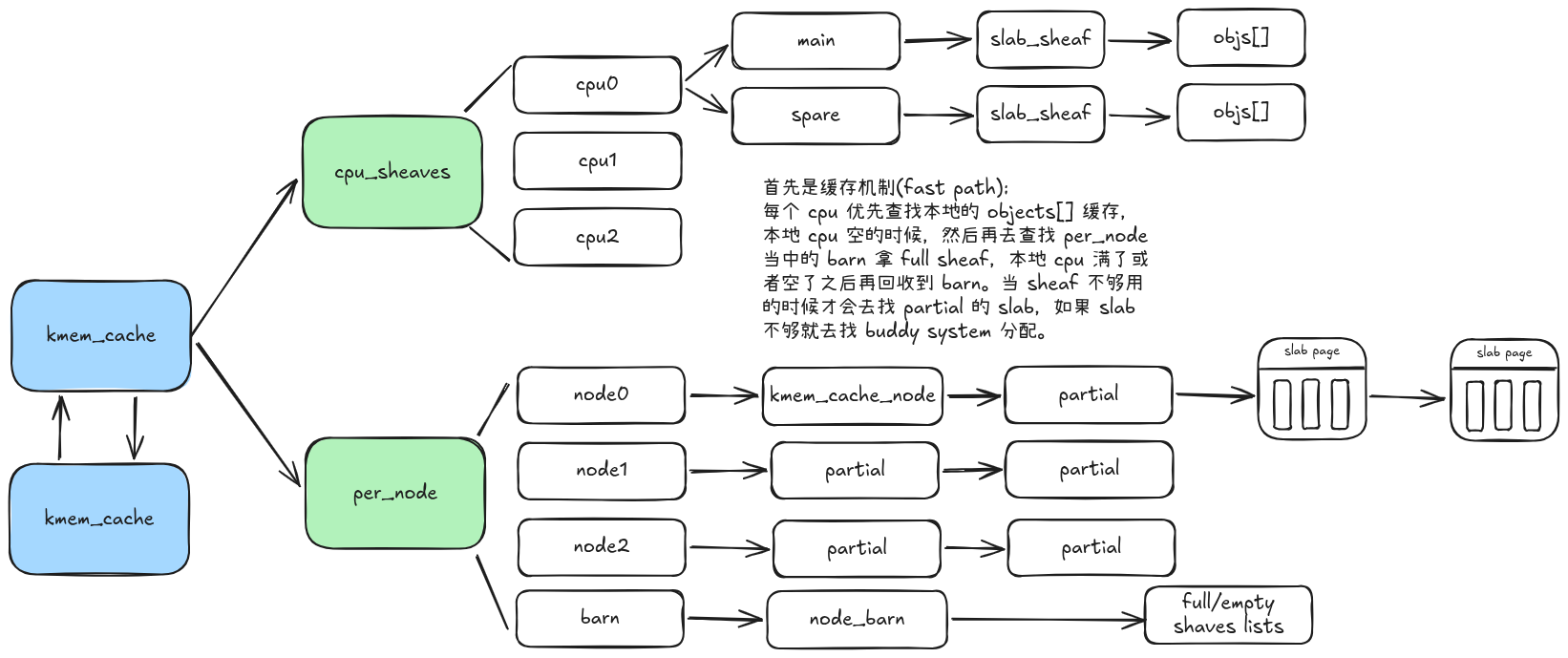
structslub_percpu_sheaves { local_trylock_t lock; structslab_sheaf *main;/* never NULL when unlocked */ structslab_sheaf *spare;/* empty or full, may be NULL */ structslab_sheaf *rcu_free;/* for batching kfree_rcu() */ };
structslab_sheaf { union { structrcu_headrcu_head; structlist_headbarn_list; /* only used for prefilled sheafs */ struct { unsignedint capacity; bool pfmemalloc; }; }; structkmem_cache *cache; unsignedint size; int node; /* only used for rcu_sheaf */ void *objects[]; };
staticunsignedint alloc_count = 3; module_param(alloc_count, uint, 0444); MODULE_PARM_DESC(alloc_count, "How many objects to allocate from the custom kmem_cache");
staticunsignedint kmalloc_request = 130; module_param(kmalloc_request, uint, 0444); MODULE_PARM_DESC(kmalloc_request, "Byte size used for the kmalloc bucket demo");
pr_info("slub_demo: sizeof(object)=%zu kmem_cache_size=%u\n", sizeof(struct slub_demo_obj), kmem_cache_size(demo_cache)); pr_info("slub_demo: ctor runs when SLUB prepares new objects, not on every alloc\n");
// 这里开始分配,分配 alloc_count 个 objects for (i = 0; i < alloc_count; i++) { demo_objs[i] = kmem_cache_alloc(demo_cache, GFP_KERNEL); if (!demo_objs[i]) return -ENOMEM;
demo_objs[i]->last_allocation_round = i + 1; dump_demo_obj("custom-cache alloc", demo_objs[i]); }
pr_info("slub_demo: ctor_calls after %u allocations = %d\n", alloc_count, atomic_read(&ctor_calls));
reused_obj->last_allocation_round = alloc_count + 1; dump_demo_obj("custom-cache re-allocation", reused_obj); if (freed_obj == reused_obj) pr_info("slub_demo: allocator returned the same address immediately after free\n"); else pr_info("slub_demo: allocator returned a different address; same-cache reuse can still occur later\n");
pr_info("slub_demo: ctor_calls after re-allocation = %d\n", atomic_read(&ctor_calls));
memset(kmalloc_buf, 0x23, kmalloc_request); pr_info("slub_demo: kmalloc request=%u actual_bucket=%zu ptr=%px\n", kmalloc_request, ksize(kmalloc_buf), kmalloc_buf); pr_info("slub_demo: for small requests, kmalloc is usually serving from a SLUB size cache rather than directly from buddy\n");