实验环境:
- 操作系统: Linux Ubuntu 24.04
- nogpu
1 pytorch 安装
本人为 no-gpu 版本.
1
| conda install pytorch torchvision torchaudio cpuonly -c pytorch
|
其他版本参考
2 机器学习的方法
2.1 监督学习
监督学习(supervised learning)是在给定目标特征的情况预测标签, 每个 “特征-标签” 的键值对称为一个样本(example), 我们最终的目标是能够生成一个模型, 该模型能够将任何的输入特征映射到标签.
https://zh.d2l.ai/chapter_introduction/index.html#id9: 举一个具体的例子: 假设我们需要预测患者的心脏病是否会发作,那么观察结果“心脏病发作”或“心脏病没有发作”将是样本的标签。 输入特征可能是生命体征,如心率、舒张压和收缩压等。
2.1.1 回归问题
回归(regression)是最简单的监督学习任务之一:
- 根据房子面积, 预测房价: 120 万
- 根据学习时间, 预测考试分数: 86.5 分
- 根据温度、湿度, 预测明天用电量: 3200 度
- 根据年龄、身高, 预测体重: 65.3 kg
关于什么是回归问题, 根据已有信息(可能有多个)预测一个具体的值.
2.1.2 分类问题
分类问题往往用来分析一个具体的趋势或者情况, 但在现实生活中我们往往还有一些其他的问题.
- 根据一张图片判断它是猫还是狗
- 判断新闻属于体育、财经、科技哪一类
关于什么是分类问题, 根据已有信息判断它属于哪一个类别的问题.
2.1.3 标记问题
笔者在学习的时候是觉得会很容易混淆的, 有人说标记问题也是一个分类问题:
这里笔者也不太了解.
from https://zhuanlan.zhihu.com/p/60606684:
标记问题的输入是一个观测序列,输出是一个标记序列或状态序列。标注问题的目标在于学习一个模型,使它能够对观测序列给出标记序列作为预测
from gpt-5.5:
分类问题像是给一整箱水果贴一个标签:
“这箱是苹果”.
标记问题像是给箱子里的每一个水果分别贴标签:
“这个是苹果,那个是香蕉,另一个是橘子”.
关于什么是标记问题, 给数据中的每个部分都打上一个标签.
2.1.4 搜索问题
有时候我们并不是需要输出一个具体的类别或者数值, 我们常常希望对一组数据进行排序.
from https://zhuanlan.zhihu.com/p/161662701:
已知智能体的初始状态和目标状态,求解一个行动序列使得智能体能从初始状态转移到目标状态,称为搜索问题
2.1.5 推荐系统
与搜索问题相类似的是推荐系统(recommender system), 它的目标是向特定的用户进行个性化的推荐.
2.1.6 序列学习
序列学习(sequence learning)处理的是带有先后顺序的数据. 它和普通分类, 回归不太一样, 因为它不只关心一个样本里有什么, 还关心这些内容出现的顺序.
比如一句话里的词是有顺序的. 我 爱 北京 和 北京 爱 我 使用了相似的词, 但是意思完全不同. 再比如股票价格, 天气变化, 用户点击记录, 音频信号, 都是按时间一步一步出现的.
序列学习常见任务包括.
- 文本生成, 根据前面的文字预测后面的文字.
- 机器翻译, 把一段中文序列变成英文序列.
- 语音识别, 把声音序列变成文字序列.
- 时间序列预测, 根据过去的温度, 销量, 股价, 预测未来数值.
- 序列标注, 给一句话中的每个词打标签.
可以把序列学习简单理解成: 模型要读一串有顺序的数据, 并且根据上下文做判断或生成结果.
Transformer 本身就是为序列学习而出名的模型. 它最开始主要用于机器翻译, 后来被广泛用于大语言模型. 大语言模型做的事情, 本质上就是根据前面的 token 序列, 预测下一个 token.
2.2 无监督学习
在监督学习当中, 我们需要向模型提供大量的数据集, 如果工作没有十分具体的目标, 我们就需要自发地去学习, 比如拿到了一堆数据, 但是我们不知道最后的目标是什么, 这类不含有目标的机器学习通常被称为无监督学习(unsupervised learning).
这类问题常见的有:
- 聚类(clustering)问题: 没有标签的情况下,我们是否能给数据分类.
- 主成分分析(principal component analysis)问题: 我们能否找到尽量少的参数来捕捉数据的相关属性?
- 因果关系(causality)和概率图模型(probabilistic graphical models)问题
- 生成对抗性网络(generative adversarial networks)
2.3 强化学习
强化学习(reinforcement learning) 是一种机器学习的过程, 其核心在于智能体通过与环境交互来学习决策机制. 可能应用于机器人, 对话系统等领域.
from https://zh.d2l.ai/chapter_introduction/index.html#id18
在强化学习问题中,智能体(agent)在一系列的时间步骤上与环境交互。 在每个特定时间点,智能体从环境接收一些观察(observation),并且必须选择一个动作(action),然后通过某种机制(有时称为执行器)将其传输回环境,最后智能体从环境中获得奖励(reward)。 此后新一轮循环开始,智能体接收后续观察,并选择后续操作,依此类推。
2.4 深度学习
深度学习(deep learning)是一种机器学习方法.
from https://www.ibm.com/cn-zh/think/topics/deep-learning#763338456
深度学习为大多数人工智能 (AI) 应用提供动力,广泛应用于图像识别、语音识别和自然语言处理 (NLP)等领域.
与传统机器学习明确定义的数学逻辑不同, 深度学习模型的神经网络由许多相互连接的神经元层组成,每个神经元都执行特定的数学运算操作.
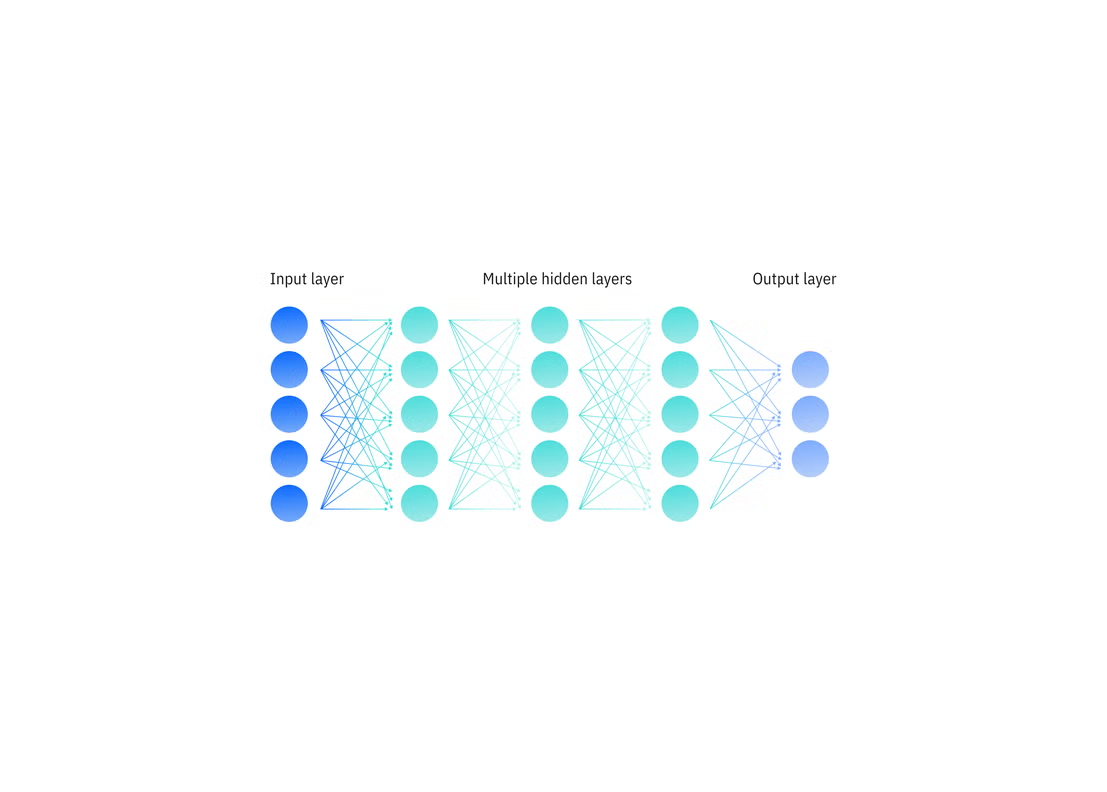
image from https://www.ibm.com/cn-zh/think/topics/deep-learning#763338456
3 线性神经网络实例
本次以 FashionMNIST 时装分类为例子.
本次模型的主体是.
它没有隐藏层, 没有复杂结构, 只有一个线性变换加一个 softmax.
softmax 是一个激活函数, 它的唯一任务就是把一组没有规律的数字, 变成一组相加等于 1 的概率值
所以它是一个非常简单的神经网络, 也可以叫单层神经网络. 但它已经包含了训练神经网络的基本流程.
Notice: 本实验的样例参考 https://zh.d2l.ai/chapter_linear-networks/softmax-regression-scratch.html
3.1 实验中的概念
Fashion-MNIST
Fashion-MNIST 是一个常见的入门图片分类数据集. 它里面是衣服, 鞋子, 包等图片.
它有 10 个类别.
1
| t-shirt, trouser, pullover, dress, coat, sandal, shirt, sneaker, bag, ankle boot.
|
每张图片大小是 28x28. 图片是灰度图, 所以每个像素只需要一个数字表示亮度.
实验中的特征
本实验中, 特征就是图片里的像素值.
一张 28x28 的图片有 784 个像素. 我们把它拉平成一行, 就得到 784 个特征.
模型就是根据这 784 个数字判断图片属于哪一类.
实验中的标签
标签表示这张图片的真实类别.
1
2
3
| 0 可能表示 t-shirt.
1 可能表示 trouser.
9 可能表示 ankle boot.
|
实验中的参数
W 决定每个像素对每个类别的影响.
b 是每个类别的基础分.
训练模型, 本质上就是不断调整 W 和 b, 让模型预测得越来越准.
3.2 从零开始实现
代码拆解
这一节的目标不是使用 PyTorch 已经封装好的神经网络层, 而是自己手写一个最简单的图片分类模型, 它可以理解成一个只有一层的神经网络.
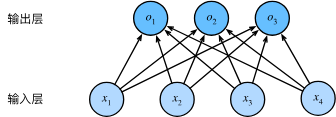
image from https://zh.d2l.ai/chapter_linear-networks/softmax-regression.html#id2
它要解决的问题是, 给模型一张 Fashion-MNIST 图片, 让模型判断这张图片属于 10 个类别中的哪一个.
整个程序可以拆成 7 个步骤.
- 加载数据.
- 初始化模型参数 W 和 b.
- 定义 softmax, 把分数变成概率.
- 定义模型 net, 也就是图片如何变成预测结果.
- 定义损失函数 cross_entropy, 判断模型的误差.
- 定义准确率 accuracy, 统计模型猜对了多少.
- 不断训练, 用梯度下降更新 W 和 b.
第一步, 加载数据
代码如下.
1
| train_iter, test_iter = load_data_fashion_mnist(batch_size)
|
Fashion-MNIST 是一个图片分类数据集. 每张图片是 28x28 的灰度图(灰度图可以理解成每个像素只有一个亮度值, 不是彩色图片).
https://github.com/zalandoresearch/fashion-mnist
一张图片有 28x28 个像素, 所以一共有 784 个数字.
训练集用来让模型学习. 测试集用来检查模型有没有真的学会.
batch_size = 256 的意思是, 模型不是一次只看 1 张图片, 而是一次看 256 张图片. 这样训练更快, 也更稳定.
每次循环取出来的数据大概长这样.
1
2
| X 的形状是 [256, 1, 28, 28].
y 的形状是 [256].
|
这里的 X 是图片, y 是答案.
比如 y[0] = 9, 可能表示第一张图片真实类别是 ankle boot.
第二步, 初始化参数 W 和 b
代码如下.
1
2
| W = torch.normal(0, 0.01, size=(num_inputs, num_outputs), requires_grad=True)
b = torch.zeros(num_outputs, requires_grad=True)
|
这个模型真正要学习的东西只有两个, W 和 b.
W 是权重矩阵, 形状是 [784, 10].
可以把 W 粗略理解为一张打分表. 每个像素都会对每个类别贡献一点分数.
b 是偏置, 形状是 [10]. 它相当于给每个类别额外加一个基础分.
requires_grad=True 表示: PyTorch 需要记录它们的计算过程, 后面要自动计算梯度, 然后更新它们.
第三步, 定义 softmax 回归
模型一开始输出的不是概率, 而是普通分数.
比如一张图片经过 X @ W + b 以后, 可能得到这样的 10 个分数.
1
| [1.2, 0.3, -0.4, 2.1, 0.8, -1.0, 0.5, 1.7, 0.2, 0.9]
|
这些数字还不能直接理解为概率. 因为它们可能是负数, 也不会加起来等于 1.
softmax 的作用就是, 把这些分数变成概率.
1
2
3
4
| def softmax(X):
X_exp = torch.exp(X)
partition = X_exp.sum(1, keepdim=True)
return X_exp / partition
|
它做了三件事.
torch.exp(X), 把每个分数变成正数.X_exp.sum(1, keepdim=True), 计算每一行的总和.X_exp / partition, 让每一行除以自己的总和.
做完以后, 每一行都会变成一组概率, 并且这一行所有概率加起来等于 1.
比如最后可能变成这样.
1
| [0.05, 0.02, 0.01, 0.38, 0.09, 0.01, 0.06, 0.25, 0.02, 0.11]
|
这表示模型认为第 4 类概率最大, 所以会预测第 4 类.
第四步, 定义模型 net
代码是这样.
1
2
3
| def net(X):
X = X.reshape((-1, W.shape[0]))
return softmax(torch.matmul(X, W) + b)
|
这就是整个模型的核心.
它可以拆成三步看.
第一步, 把图片拉平.
1
| X = X.reshape((-1, W.shape[0]))
|
原来的图片形状是.
拉平以后变成.
意思是, 这一批有 256 张图片, 每张图片用 784 个数字表示.
第二步, 计算类别分数.
形状变化是.
1
| [256, 784] @ [784, 10] -> [256, 10]
|
也就是说, 每张图片都会得到 10 个类别分数.
第三步, 把分数变成概率.
最终输出形状还是 [256, 10], 但是里面的值已经是概率.
第五步, 定义交叉熵损失
代码如下.
1
2
| def cross_entropy(y_hat, y):
return -torch.log(y_hat[range(len(y_hat)), y])
|
y_hat 是模型预测的概率.
比如一批有 3 张图片, 每张图片有 10 个类别概率.
y 是真实答案.
这表示.
1
2
3
| 第 1 张图片真实类别是 0.
第 2 张图片真实类别是 2.
第 3 张图片真实类别是 5.
|
这一句最关键.
1
| y_hat[range(len(y_hat)), y]
|
它的意思是, 从每一行里取出真实类别对应的预测概率.
如果模型对真实类别很有信心, 比如概率是 0.9, 那么损失会很小.
如果模型对真实类别很没信心, 比如概率是 0.01, 那么损失会很大.
-torch.log(...) 的作用就是把概率变成损失.
这个函数返回的不是一个数字, 而是一批图片每张各自的 loss. 如果一批有 256 张图片, 它就返回 256 个 loss.
第六步, 定义准确率 accuracy
代码是这样.
1
2
3
4
5
| def accuracy(y_hat, y):
if len(y_hat.shape) > 1 and y_hat.shape[1] > 1:
y_hat = y_hat.argmax(axis=1)
cmp = y_hat.type(y.dtype) == y
return float(cmp.type(y.dtype).sum())
|
模型输出的是 10 个类别的概率. 但是最终预测时, 我们只选概率最大的那个类别.
这句就是找每一张图片概率最大的类别编号.
比如概率是.
最大的是第 2 号位置, 所以预测类别就是 2.
然后拿预测类别和真实标签比较.
1
| cmp = y_hat.type(y.dtype) == y
|
如果预测对了就是 True, 错了就是 False.
最后把 True 当成 1, False 当成 0, 求和就得到猜对了多少张.
第七步, Accumulator 是干什么的
训练时我们需要不断统计三个数.
所以代码里写了一个简单累加器.
它里面一开始是.
每训练一批, 就把这一批的数据加进去.
1
| metric.add(float(loss.sum().detach()), accuracy(y_hat, y), y.numel())
|
这三个位置分别表示.
1
2
3
| metric[0], 累计总损失.
metric[1], 累计猜对数量.
metric[2], 累计样本数量.
|
最后平均训练损失这样算.
1
| train_loss = metric[0] / metric[2]
|
训练准确率这样算.
1
| train_acc = metric[1] / metric[2]
|
第八步, 训练一轮 train_epoch
训练一轮的意思是, 把训练集里的所有图片都看一遍.
核心代码是.
1
2
3
4
5
| for X, y in train_iter:
y_hat = net_fn(X)
loss = loss_fn(y_hat, y)
loss.sum().backward()
update_fn(X.shape[0])
|
这几行就是机器学习训练最核心的流程.
1
| 预测 -> 算损失 -> 算梯度 -> 更新参数.
|
y_hat = net_fn(X) 是预测.
loss = loss_fn(y_hat, y) 是看预测错得多严重.
loss.sum().backward() 是让 PyTorch 自动计算梯度.
update_fn(X.shape[0]) 是根据梯度更新 W 和 b.
第九步, updater 如何更新参数
代码是这样.
1
2
3
4
5
| def updater(batch_size):
with torch.no_grad():
for param in [W, b]:
param -= lr * param.grad / batch_size
param.grad.zero_()
|
它做的是手写 随机梯度下降(SGD, Stochastic Gradient Descent).
SGD 解释: https://www.ibm.com/cn-zh/think/topics/stochastic-gradient-descent
SGD 的直觉是, 如果梯度告诉我们参数往某个方向会让 loss 变大, 那我们就往反方向走一点.
公式可以粗略理解为.
这里除以 batch_size, 是因为前面用了 loss.sum().backward(), 得到的是一整批样本的梯度总和, 除以 batch size 后相当于取平均.
param.grad.zero_() 很重要. PyTorch 默认会累加梯度, 如果不清零, 下一批的梯度会和上一批混在一起.
第十步, train 训练多轮
代码是这样.
1
2
3
| for epoch in range(epochs):
train_loss, train_acc = train_epoch(...)
test_acc = evaluate_accuracy(...)
|
一轮 epoch 是完整看一遍训练集.
num_epochs = 10 的意思是, 完整训练集会被看 10 遍.
每一轮结束后, 代码会打印三个指标.
1
2
3
| train_loss, 训练损失.
train_acc, 训练准确率.
test_acc, 测试准确率.
|
一般来说, 训练过程中我们希望看到.
1
2
3
| train_loss 慢慢下降.
train_acc 慢慢上升.
test_acc 大体上升, 但可能会有波动.
|
第十一步, predict 看预测结果
训练结束后, 代码会拿测试集里的几张图片做预测.
它会打印类似这样的结果.
1
2
| 真实: ankle boot 预测: ankle boot
真实: pullover 预测: pullover
|
如果真实标签和预测标签一样, 说明这张图片预测对了.
总结
这个从零实现的版本, 重点不是追求最高准确率, 而是让我们看清楚神经网络训练到底发生了什么.
它的核心可以压缩成一句话.
1
| 图片 X -> 计算 X @ W + b -> softmax 得到概率 -> cross_entropy 算损失 -> backward 算梯度 -> SGD 更新 W 和 b.
|
这里虽然模型很简单, 但已经包含了神经网络训练的基本骨架. 后面的多层感知机, 卷积神经网络, Transformer, 本质上也都有类似的训练流程, 只是模型本体 net 会变得更复杂.
完整代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
| import torch
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
batch_size = 256
num_inputs = 784
num_outputs = 10
num_epochs = 10
lr = 0.1
fashion_mnist_labels = [
"t-shirt",
"trouser",
"pullover",
"dress",
"coat",
"sandal",
"shirt",
"sneaker",
"bag",
"ankle boot",
]
def load_data_fashion_mnist(batch_size):
"""下载并加载 Fashion-MNIST 数据集.
train_iter: 训练集迭代器,用来训练模型.
test_iter: 测试集迭代器,用来检查模型学得好不好.
每次从迭代器里取出来的是:
X: 一批图片,形状大概是 [256, 1, 28, 28]
y: 这批图片的真实标签,形状大概是 [256]
"""
transform = transforms.ToTensor()
train_dataset = datasets.FashionMNIST(
root="./data", train=True, transform=transform, download=True
)
test_dataset = datasets.FashionMNIST(
root="./data", train=False, transform=transform, download=True
)
train_iter = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_iter = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
return train_iter, test_iter
def softmax(X):
"""把分数变成概率.
输入 X 的形状是 [批量大小, 10].
每一行代表一张图片的 10 个类别分数.
softmax 做完后:
- 每个数都变成 0 到 1 之间的概率
- 每一行的概率加起来等于 1
"""
X_exp = torch.exp(X)
partition = X_exp.sum(1, keepdim=True)
return X_exp / partition
def net(X):
"""模型本体:输入图片,输出 10 个类别的概率.
这行代码等价于:
1. 把图片从 [批量大小, 1, 28, 28] 拉平成 [批量大小, 784]
2. 用 X @ W + b 算出 10 个类别分数
3. 用 softmax 把分数变成概率
"""
X = X.reshape((-1, W.shape[0]))
return softmax(torch.matmul(X, W) + b)
def cross_entropy(y_hat, y):
"""交叉熵损失.
y_hat: 模型预测的概率,形状是 [批量大小, 10]
y: 真实标签,形状是 [批量大小]
核心思想:只看真实类别对应的概率.
- 真实类别概率越高,loss 越小
- 真实类别概率越低,loss 越大
"""
return -torch.log(y_hat[range(len(y_hat)), y])
def accuracy(y_hat, y):
"""计算这一批图片里预测正确的数量."""
if len(y_hat.shape) > 1 and y_hat.shape[1] > 1:
y_hat = y_hat.argmax(axis=1)
cmp = y_hat.type(y.dtype) == y
return float(cmp.type(y.dtype).sum())
class Accumulator:
"""简单累加器.
训练时我们要累计三件事:
1. 总损失
2. 猜对了多少张
3. 总共看了多少张
"""
def __init__(self, n):
self.data = [0.0] * n
def add(self, *args):
self.data = [a + float(b) for a, b in zip(self.data, args)]
def reset(self):
self.data = [0.0] * len(self.data)
def __getitem__(self, idx):
return self.data[idx]
def evaluate_accuracy(net_fn, data_iter):
"""在测试集上计算准确率.
torch.no_grad() 表示这里只看结果,不计算梯度,也不更新参数.
"""
metric = Accumulator(2)
with torch.no_grad():
for X, y in data_iter:
metric.add(accuracy(net_fn(X), y), y.numel())
return metric[0] / metric[1]
def updater(batch_size):
"""手写小批量随机梯度下降 SGD.
参数更新可以粗略理解为:
新参数 = 旧参数 - 学习率 * 梯度
这里更新的参数只有两个:W 和 b.
"""
with torch.no_grad():
for param in [W, b]:
param -= lr * param.grad / batch_size
param.grad.zero_()
def train_epoch(net_fn, train_iter, loss_fn, update_fn):
"""训练一轮.
一轮 epoch 的意思是:把训练集里的所有图片都看一遍.
"""
metric = Accumulator(3)
for X, y in train_iter:
y_hat = net_fn(X)
loss = loss_fn(y_hat, y)
loss.sum().backward()
update_fn(X.shape[0])
metric.add(float(loss.sum().detach()), accuracy(y_hat, y), y.numel())
train_loss = metric[0] / metric[2]
train_acc = metric[1] / metric[2]
return train_loss, train_acc
def train(net_fn, train_iter, test_iter, loss_fn, epochs, update_fn):
"""训练多轮,并打印每轮的训练损失,训练准确率,测试准确率."""
for epoch in range(epochs):
train_loss, train_acc = train_epoch(net_fn, train_iter, loss_fn, update_fn)
test_acc = evaluate_accuracy(net_fn, test_iter)
print(
f"epoch {epoch + 1:02d}: "
f"train_loss={train_loss:.4f}, "
f"train_acc={train_acc:.4f}, "
f"test_acc={test_acc:.4f}"
)
def predict(net_fn, test_iter, n=6):
"""训练结束后,拿几张测试图片看看真实标签和预测标签."""
for X, y in test_iter:
break
trues = [fashion_mnist_labels[int(i)] for i in y]
preds = [fashion_mnist_labels[int(i)] for i in net_fn(X).argmax(axis=1)]
print("\n预测示例:")
for i in range(n):
print(f"{i + 1}. 真实: {trues[i]:10s} 预测: {preds[i]}")
if __name__ == "__main__":
torch.manual_seed(0)
print("加载 Fashion-MNIST 数据集...")
train_iter, test_iter = load_data_fashion_mnist(batch_size)
print("初始化模型参数...")
W = torch.normal(0, 0.01, size=(num_inputs, num_outputs), requires_grad=True)
b = torch.zeros(num_outputs, requires_grad=True)
print("开始训练...")
train(net, train_iter, test_iter, cross_entropy, num_epochs, updater)
predict(net, test_iter)
|
代码结果如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| 加载 Fashion-MNIST 数据集...
初始化模型参数...
开始训练...
epoch 01: train_loss=0.7843, train_acc=0.7490, test_acc=0.7821
epoch 02: train_loss=0.5712, train_acc=0.8124, test_acc=0.8108
epoch 03: train_loss=0.5252, train_acc=0.8255, test_acc=0.8204
epoch 04: train_loss=0.5008, train_acc=0.8316, test_acc=0.8102
epoch 05: train_loss=0.4852, train_acc=0.8369, test_acc=0.8263
epoch 06: train_loss=0.4735, train_acc=0.8404, test_acc=0.8099
epoch 07: train_loss=0.4653, train_acc=0.8431, test_acc=0.8274
epoch 08: train_loss=0.4582, train_acc=0.8457, test_acc=0.8183
epoch 09: train_loss=0.4524, train_acc=0.8461, test_acc=0.8304
epoch 10: train_loss=0.4477, train_acc=0.8483, test_acc=0.8240
预测示例:
1. 真实: ankle boot 预测: ankle boot
2. 真实: pullover 预测: pullover
3. 真实: trouser 预测: trouser
4. 真实: trouser 预测: trouser
5. 真实: shirt 预测: shirt
6. 真实: trouser 预测: trouser
|
3.3 API 实现
代码拆解
上一节是从零开始写 softmax 回归, 我们自己写了 W, b, softmax, cross_entropy, updater. 这样做适合学习原理, 但是实际写项目时一般不会这么写.
在真实项目里, 我们通常会使用 PyTorch 的 API. PyTorch 已经帮我们封装好了常见模块, 我们只需要把这些模块组合起来.
从零实现和 API 实现的对应关系大概是这样.
1
2
3
4
| 手写 W 和 b -> torch.nn.Linear.
手写 softmax + cross_entropy -> torch.nn.CrossEntropyLoss.
手写 updater -> torch.optim.SGD.
手写 net 函数 -> torch.nn.Sequential.
|
核心思路
API 版本仍然在做同一件事.
1
| 图片 -> 拉平 -> 线性层 -> 输出 10 类分数 -> 计算损失 -> 更新参数.
|
但是有一个重要区别.
从零实现里, 我们在 net 里手动调用了 softmax.
API 版本里, 一般不要在模型最后手动写 softmax. 因为 torch.nn.CrossEntropyLoss 内部已经包含了 softmax 和 log 相关计算, 而且它的数值稳定性更好.
所以 API 的模型通常直接输出原始分数, 也叫 logits.
1
| 模型输出 logits, CrossEntropyLoss 负责把 logits 和真实标签变成 loss.
|
第一步, 定义模型
1
2
3
4
| net = torch.nn.Sequential(
torch.nn.Flatten(),
torch.nn.Linear(784, 10)
)
|
torch.nn.Flatten() 的作用是把图片拉平.
1
| [批量大小, 1, 28, 28] -> [批量大小, 784].
|
torch.nn.Linear(784, 10) 的作用就是线性层.
它内部自己维护了权重和偏置, 等价于从零实现里的 W 和 b.
从数学上看, 它仍然是在做.
只是这次不用我们手动创建 W 和 b.
第二步, 初始化参数
如果想尽量和从零实现保持一致, 可以手动初始化线性层的参数.
1
2
3
4
5
| def init_weights(m):
if type(m) == torch.nn.Linear:
torch.nn.init.normal_(m.weight, std=0.01)
net.apply(init_weights)
|
这里的 m 可以理解为模型里的每一层.
如果某一层是 torch.nn.Linear, 就把它的权重初始化成均值为 0, 标准差为 0.01 的正态分布.
偏置通常默认初始化为 0, 这里可以不额外写.
第三步, 定义损失函数
API 版本一般这样写.
1
| loss = torch.nn.CrossEntropyLoss()
|
注意, 它接收的是模型输出的原始分数 logits, 不是 softmax 之后的概率.
也就是说, 如果使用 CrossEntropyLoss, 模型最后不要写.
否则就相当于重复处理概率, 训练效果可能变差.
可以这样理解.
1
2
| 从零实现, net 输出概率, cross_entropy 只做 -log.
API, net 输出分数, CrossEntropyLoss 内部完成 softmax 和 -log.
|
第四步, 定义优化器
从零实现里, 我们自己写了.
1
| param -= lr * param.grad / batch_size
|
API 版本里, PyTorch 帮我们封装成优化器.
1
| trainer = torch.optim.SGD(net.parameters(), lr=0.1)
|
net.parameters() 会自动拿到模型里所有需要训练的参数. 对这个例子来说, 主要就是线性层里的权重和偏置.
第五步, 训练循环
API 版本的训练循环通常长这样.
1
2
3
4
5
6
| for X, y in train_iter:
y_hat = net(X)
l = loss(y_hat, y)
trainer.zero_grad()
l.backward()
trainer.step()
|
这几行和从零实现是一一对应的.
1
2
3
4
5
| y_hat = net(X), 前向传播, 得到预测分数.
l = loss(y_hat, y), 计算损失.
trainer.zero_grad(), 清空上一批梯度.
l.backward(), 反向传播, 计算梯度.
trainer.step(), 根据梯度更新参数.
|
这里有一个细节. API 版本的 CrossEntropyLoss 默认返回的是平均 loss, 所以一般直接写 l.backward().
从零实现里我们返回的是每张图片一个 loss, 所以前面写的是 loss.sum().backward().
完整实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
| import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
batch_size = 256
num_epochs = 10
lr = 0.1
fashion_mnist_labels = [
"t-shirt",
"trouser",
"pullover",
"dress",
"coat",
"sandal",
"shirt",
"sneaker",
"bag",
"ankle boot",
]
def load_data_fashion_mnist(batch_size):
"""加载 Fashion-MNIST 数据集."""
transform = transforms.ToTensor()
train_dataset = datasets.FashionMNIST(
root="./data", train=True, transform=transform, download=True
)
test_dataset = datasets.FashionMNIST(
root="./data", train=False, transform=transform, download=True
)
train_iter = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_iter = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
return train_iter, test_iter
def init_weights(module):
"""初始化线性层权重, 尽量和从零实现保持一致."""
if isinstance(module, nn.Linear):
nn.init.normal_(module.weight, mean=0.0, std=0.01)
nn.init.zeros_(module.bias)
def accuracy(y_hat, y):
"""计算这一批数据预测正确的数量."""
if len(y_hat.shape) > 1 and y_hat.shape[1] > 1:
y_hat = y_hat.argmax(axis=1)
cmp = y_hat.type(y.dtype) == y
return float(cmp.type(y.dtype).sum())
class Accumulator:
"""累加多个指标."""
def __init__(self, n):
self.data = [0.0] * n
def add(self, *args):
self.data = [a + float(b) for a, b in zip(self.data, args)]
def __getitem__(self, idx):
return self.data[idx]
def evaluate_accuracy(net, data_iter):
"""在测试集上计算准确率."""
net.eval()
metric = Accumulator(2)
with torch.no_grad():
for X, y in data_iter:
metric.add(accuracy(net(X), y), y.numel())
return metric[0] / metric[1]
def train_epoch(net, train_iter, loss, trainer):
"""训练一轮."""
net.train()
metric = Accumulator(3)
for X, y in train_iter:
y_hat = net(X)
l = loss(y_hat, y)
trainer.zero_grad()
l.backward()
trainer.step()
metric.add(float(l.detach()) * y.numel(), accuracy(y_hat, y), y.numel())
train_loss = metric[0] / metric[2]
train_acc = metric[1] / metric[2]
return train_loss, train_acc
def train(net, train_iter, test_iter, loss, trainer, num_epochs):
"""训练多轮并打印指标."""
for epoch in range(num_epochs):
train_loss, train_acc = train_epoch(net, train_iter, loss, trainer)
test_acc = evaluate_accuracy(net, test_iter)
print(
f"epoch {epoch + 1:02d}: "
f"train_loss={train_loss:.4f}, "
f"train_acc={train_acc:.4f}, "
f"test_acc={test_acc:.4f}"
)
def predict(net, test_iter, n=6):
"""打印几条预测结果."""
net.eval()
for X, y in test_iter:
break
with torch.no_grad():
preds = net(X).argmax(axis=1)
trues = [fashion_mnist_labels[int(i)] for i in y]
preds = [fashion_mnist_labels[int(i)] for i in preds]
print("\n预测示例:")
for i in range(n):
print(f"{i + 1}. 真实: {trues[i]:10s} 预测: {preds[i]}")
if __name__ == "__main__":
torch.manual_seed(0)
print("加载 Fashion-MNIST 数据集...")
train_iter, test_iter = load_data_fashion_mnist(batch_size)
print("创建模型...")
net = nn.Sequential(
nn.Flatten(),
nn.Linear(784, 10),
)
net.apply(init_weights)
loss = nn.CrossEntropyLoss()
trainer = torch.optim.SGD(net.parameters(), lr=lr)
print("开始训练...")
train(net, train_iter, test_iter, loss, trainer, num_epochs)
predict(net, test_iter)
|
代码结果如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| 加载 Fashion-MNIST 数据集...
创建模型...
开始训练...
epoch 01: train_loss=0.7857, train_acc=0.7492, test_acc=0.7864
epoch 02: train_loss=0.5687, train_acc=0.8135, test_acc=0.8109
epoch 03: train_loss=0.5258, train_acc=0.8253, test_acc=0.8124
epoch 04: train_loss=0.5014, train_acc=0.8320, test_acc=0.8219
epoch 05: train_loss=0.4859, train_acc=0.8363, test_acc=0.8224
epoch 06: train_loss=0.4739, train_acc=0.8396, test_acc=0.8264
epoch 07: train_loss=0.4652, train_acc=0.8419, test_acc=0.8274
epoch 08: train_loss=0.4583, train_acc=0.8449, test_acc=0.8337
epoch 09: train_loss=0.4515, train_acc=0.8469, test_acc=0.8275
epoch 10: train_loss=0.4477, train_acc=0.8483, test_acc=0.8253
预测示例:
1. 真实: ankle boot 预测: ankle boot
2. 真实: pullover 预测: pullover
3. 真实: trouser 预测: trouser
4. 真实: trouser 预测: trouser
5. 真实: shirt 预测: shirt
6. 真实: trouser 预测: trouser
|
References
https://zh.d2l.ai/chapter_preface/index.html
https://github.com/datawhalechina/happy-llm
https://www.ibm.com/cn-zh/think/machine-learning#605511093