实验环境:
操作系统: Linux Ubuntu 24.04
nogpu
1 线性神经网络 上一节中, 我们以 FashionMNIST 为例做了一个线性神经网络. 线性神经网络是结构最简单的神经网络, 其特点是: 激活函数纯为线性函数, 其输出可以是任意连续的实数值. 由于没有非线性激活函数的变换, 多层的线性神经网络在数学上完全可以转换为单层网络.
例如, 在该例子中.
我们的结构为只有输入层和输出层的单层神经网络:
输入层为 784 个神经元, Fashion-MNIST 的单张图片尺寸是 28 x 28 像素. 代码在输入时通过 X.reshape((-1, W.shape[0])) 将二维图像直接拉平(Flatten)成了一维的长条向量. 这 784 个像素点, 每一个点都对应输入层的一个接收节点.
输出层有 10 个神经元, 因为任务是要把衣服鞋包分为 10 个类别. 输出层的这 10 个神经元, 每一个神经元都负责计算出当前图片属于某一个特定类别的得分. 经过末端的 Softmax 激活后, 这 10 个神经元最终输出的就是 10 个概率值.
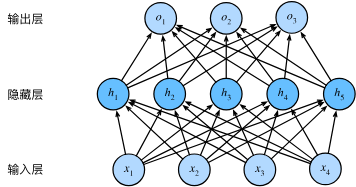
2 多层感知机 如果我们在线性神经网络当中加入非线性函数, 并堆叠多个隐藏层, 那么它就变成了多层感知机(Multilayer Perceptron, MLP), 者也就是最基础的深度前馈神经网络(DNN).
image from https://zh.d2l.ai/chapter_multilayer-perceptrons/mlp.html#id4
激活函数
输出范围
ReLU
[0, +∞)
pReLU
(-∞, +∞)
sigmoid
(0, 1)
tanh
(-1, 1)
2.1 非线性的激活函数 3 更多的演化方向 卷积神经网络, 在多层网络的基础上, 为了处理图像等数据信息, 引入卷积运算, 就变成了卷积神经网络(CNN).
如果在网络当中引入反馈环路, 就变成了循环神经网络(RNN)以及更高级的其他网络.
在 RNN 之后, 为了解决无法并行计算和长距离记忆丢失的问题, 改用了注意力机制, 就演变成了如今的大模型, 核心为 Transformer.
4 多层感知机实例从零开始 这里预热一下知识, 我们说多层感知机是从线性到非线性的过程.
来观察一下本次模型的整个函数表达, 先用符号把代码对应起来:
1 2 3 4 5 6 7 X: 一批输入图片, 每一行是一张图片 W1: 第一层权重, 形状是 [784, 256] b1: 第一层偏置, 形状是 [256] H: 隐藏层输出, 形状是 [batch_size, 256] W2: 第二层权重, 形状是 [256, 10] b2: 第二层偏置, 形状是 [10] O: 输出层结果, 形状是 [batch_size, 10]
如果只是加一个隐藏层, 但不加激活函数, 计算会是这样:
1 2 H = X @ W1 + b1 O = H @ W2 + b2
把 H 代入第二行:
1 O = (X @ W1 + b1) @ W2 + b2
展开以后可以写成:
1 O = X @ (W1 @ W2) + (b1 @ W2 + b2)
这里的 W1 @ W2 可以看成一个新的权重 W, b1 @ W2 + b2 可以看成一个新的偏置 b, 所以整体又变成了:
这说明, 如果中间没有非线性激活函数, 哪怕堆很多个全连接层, 最后仍然等价于一个单层线性模型. 也就是说, 只是多写几层 Linear, 并不会让模型真正变强.
所以 MLP 的关键不是层数多, 而是在线性变换后面加入非线性激活函数:
1 2 H = ReLU(X @ W1 + b1) O = H @ W2 + b2
对应到代码就是:
1 2 H = relu(X @ W1 + b1) return H @ W2 + b2
ReLU 会逐元素处理隐藏层的每个值:
因为中间多了这个非线性操作, H 不再只是 X 的线性变换, 所以后面的输出层也不能再和前面的隐藏层简单合并成一个线性层. 这就是 MLP 能够学习更复杂关系的核心原因.
从代码角度看, softmax 回归是:
1 X -> Linear(784, 10) -> logits
MLP 是:
1 X -> Linear(784, 256) -> ReLU -> Linear(256, 10) -> logits
也就是说, MLP 多出来的隐藏层 H 可以学习中间表示, 比如图片中的边缘, 轮廓, 局部形状等特征, 输出层再根据这些隐藏特征做最终分类.
如果继续堆叠隐藏层, 就会变成更深的网络:
1 X -> Linear -> ReLU -> Linear -> ReLU -> Linear -> 输出
这种结构就是更一般的深度神经网络 DNN. 每一层都先做线性变换, 再用激活函数加入非线性, 让模型逐层学习更复杂的表示.
4.1 代码拆解 这一版叫从零开始实现, 是因为模型参数和前向传播都由我们自己写.
整体结构是:
1 2 3 4 5 6 输入图片 [batch_size, 1, 28, 28] -> reshape 成 [batch_size, 784] -> 第一层全连接, 784 -> 256 -> ReLU 激活函数 -> 第二层全连接, 256 -> 10 -> CrossEntropyLoss 内部处理 softmax 和交叉熵
4.1.1 超参数 1 2 3 4 5 6 batch_size = 256 num_inputs = 784 num_outputs = 10 num_hiddens = 256 num_epochs = 10 lr = 0.1
batch_size = 256, 每次训练看 256 张图片.num_inputs = 784, 每张图片是 28 x 28, 拉平后是 784 个输入特征.num_outputs = 10, Fashion-MNIST 有 10 个类别.num_hiddens = 256, 隐藏层有 256 个神经元.num_epochs = 10, 完整训练集看 10 遍.lr = 0.1, SGD 更新参数时的步长.
4.1.2 数据加载 load_data_fashion_mnist 使用 torchvision.datasets.FashionMNIST 加载数据.
1 transform = transforms.ToTensor()
这一步把图片转成张量, 单张图片形状是 [1, 28, 28], 经过 DataLoader 组合后, 一个批量的形状是 [256, 1, 28, 28].
4.1.3 参数初始化 1 2 3 4 5 W1 = nn.Parameter(torch.randn(num_inputs, num_hiddens) * 0.01 ) b1 = nn.Parameter(torch.zeros(num_hiddens)) W2 = nn.Parameter(torch.randn(num_hiddens, num_outputs) * 0.01 ) b2 = nn.Parameter(torch.zeros(num_outputs)) params = [W1, b1, W2, b2]
参数形状是:
1 2 3 4 W1: [784, 256] b1: [256] W2: [256, 10] b2: [10]
nn.Parameter 表示这些张量是可训练参数, PyTorch 会为它们记录梯度.
4.1.4 ReLU 激活函数 1 2 3 def relu (X ): a = torch.zeros_like(X) return torch.max (X, a)
ReLU 的规则是:
1 2 x > 0, 输出 x x <= 0, 输出 0
它的作用是加入非线性. 如果没有 ReLU, 两个线性层叠起来仍然等价于一个线性层, 模型本质上还是 softmax 回归.
4.1.5 模型前向传播 1 2 3 4 def net (X ): X = X.reshape((-1 , num_inputs)) H = relu(X @ W1 + b1) return H @ W2 + b2
第一行把图片拉平:
1 [batch_size, 1, 28, 28] -> [batch_size, 784]
第二行计算隐藏层:
1 [batch_size, 784] @ [784, 256] + [256] -> [batch_size, 256]
第三行计算输出层:
1 [batch_size, 256] @ [256, 10] + [10] -> [batch_size, 10]
输出的 10 个数是 logits, 也就是还没有显式 softmax 的原始类别分数.
4.1.6 损失函数 1 loss = nn.CrossEntropyLoss(reduction="none" )
这里没有在 net 里面写 softmax, 因为 CrossEntropyLoss 内部已经包含 LogSoftmax + NLLLoss, 训练时直接喂 logits 即可.
4.1.7 训练流程 每个 batch 的训练步骤是:
1 2 3 4 5 1. y_hat = net(X), 前向传播 2. loss = loss_fn(y_hat, y), 计算损失 3. trainer.zero_grad(), 清空旧梯度 4. loss.mean().backward(), 反向传播 5. trainer.step(), 更新 W1, b1, W2, b2
和 softmax 回归相比, 这个 MLP 多了隐藏层和 ReLU:
1 2 softmax 回归: 784 -> 10 MLP: 784 -> 256 -> 10
4.2 完整代码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 import torchfrom torch import nnfrom torch.utils.data import DataLoaderfrom torchvision import datasets, transformsbatch_size = 256 num_inputs = 784 num_outputs = 10 num_hiddens = 256 num_epochs = 10 lr = 0.1 fashion_mnist_labels = [ "t-shirt" , "trouser" , "pullover" , "dress" , "coat" , "sandal" , "shirt" , "sneaker" , "bag" , "ankle boot" , ] def load_data_fashion_mnist (batch_size ): """下载并加载 Fashion-MNIST 数据集.""" transform = transforms.ToTensor() train_dataset = datasets.FashionMNIST( root="./data" , train=True , transform=transform, download=True ) test_dataset = datasets.FashionMNIST( root="./data" , train=False , transform=transform, download=True ) train_iter = DataLoader(train_dataset, batch_size=batch_size, shuffle=True ) test_iter = DataLoader(test_dataset, batch_size=batch_size, shuffle=False ) return train_iter, test_iter def relu (X ): """手写 ReLU 激活函数: 小于 0 的值变成 0, 大于 0 的值保留.""" a = torch.zeros_like(X) return torch.max (X, a) def net (X ): """单隐藏层 MLP. 1. 把图片从 [批量大小, 1, 28, 28] 拉平成 [批量大小, 784] 2. 第一层: 784 -> 256 3. ReLU: 加入非线性能力 4. 第二层: 256 -> 10 返回的是 10 个类别的原始分数 logits, softmax 由 CrossEntropyLoss 内部处理. """ X = X.reshape((-1 , num_inputs)) H = relu(X @ W1 + b1) return H @ W2 + b2 def accuracy (y_hat, y ): """计算这一批图片里预测正确的数量.""" if len (y_hat.shape) > 1 and y_hat.shape[1 ] > 1 : y_hat = y_hat.argmax(axis=1 ) cmp = y_hat.type (y.dtype) == y return float (cmp.type (y.dtype).sum ()) class Accumulator : """简单累加器, 用来累计损失, 正确数量, 样本数量.""" def __init__ (self, n ): self .data = [0.0 ] * n def add (self, *args ): self .data = [a + float (b) for a, b in zip (self .data, args)] def __getitem__ (self, idx ): return self .data[idx] def evaluate_accuracy (net_fn, data_iter ): """在测试集上计算准确率.""" metric = Accumulator(2 ) with torch.no_grad(): for X, y in data_iter: metric.add(accuracy(net_fn(X), y), y.numel()) return metric[0 ] / metric[1 ] def train_epoch (net_fn, train_iter, loss_fn, trainer ): """训练一轮.""" metric = Accumulator(3 ) for X, y in train_iter: y_hat = net_fn(X) loss = loss_fn(y_hat, y) trainer.zero_grad() loss.mean().backward() trainer.step() metric.add(float (loss.sum ().detach()), accuracy(y_hat, y), y.numel()) train_loss = metric[0 ] / metric[2 ] train_acc = metric[1 ] / metric[2 ] return train_loss, train_acc def train (net_fn, train_iter, test_iter, loss_fn, trainer, epochs ): """训练多轮, 并打印每轮的训练损失, 训练准确率, 测试准确率.""" for epoch in range (epochs): train_loss, train_acc = train_epoch(net_fn, train_iter, loss_fn, trainer) test_acc = evaluate_accuracy(net_fn, test_iter) print ( f"epoch {epoch + 1 :02d} : " f"train_loss={train_loss:.4 f} , " f"train_acc={train_acc:.4 f} , " f"test_acc={test_acc:.4 f} " ) def predict (net_fn, test_iter, n=6 ): """训练结束后, 拿几张测试图片看看真实标签和预测标签.""" for X, y in test_iter: break with torch.no_grad(): preds = net_fn(X).argmax(axis=1 ) trues = [fashion_mnist_labels[int (i)] for i in y] preds = [fashion_mnist_labels[int (i)] for i in preds] print ("\n预测示例:" ) for i in range (n): print (f"{i + 1 } . 真实: {trues[i]:10s} 预测: {preds[i]} " ) if __name__ == "__main__" : torch.manual_seed(0 ) print ("加载 Fashion-MNIST 数据集..." ) train_iter, test_iter = load_data_fashion_mnist(batch_size) print ("初始化 MLP 模型参数..." ) W1 = nn.Parameter(torch.randn(num_inputs, num_hiddens) * 0.01 ) b1 = nn.Parameter(torch.zeros(num_hiddens)) W2 = nn.Parameter(torch.randn(num_hiddens, num_outputs) * 0.01 ) b2 = nn.Parameter(torch.zeros(num_outputs)) params = [W1, b1, W2, b2] loss = nn.CrossEntropyLoss(reduction="none" ) trainer = torch.optim.SGD(params, lr=lr) print ("开始训练..." ) train(net, train_iter, test_iter, loss, trainer, num_epochs) predict(net, test_iter)
代码运行.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 加载 Fashion-MNIST 数据集... 初始化 MLP 模型参数... 开始训练... epoch 01: train_loss=1.0488, train_acc=0.6350, test_acc=0.7506 epoch 02: train_loss=0.6014, train_acc=0.7886, test_acc=0.7760 epoch 03: train_loss=0.5231, train_acc=0.8166, test_acc=0.8100 epoch 04: train_loss=0.4834, train_acc=0.8310, test_acc=0.8282 epoch 05: train_loss=0.4564, train_acc=0.8395, test_acc=0.8287 epoch 06: train_loss=0.4338, train_acc=0.8470, test_acc=0.8261 epoch 07: train_loss=0.4200, train_acc=0.8529, test_acc=0.8371 epoch 08: train_loss=0.4037, train_acc=0.8572, test_acc=0.8375 epoch 09: train_loss=0.3931, train_acc=0.8610, test_acc=0.8376 epoch 10: train_loss=0.3842, train_acc=0.8651, test_acc=0.8503 预测示例: 1. 真实: ankle boot 预测: ankle boot 2. 真实: pullover 预测: pullover 3. 真实: trouser 预测: trouser 4. 真实: trouser 预测: trouser 5. 真实: shirt 预测: shirt 6. 真实: trouser 预测: trouser
5 多层感知机实例 API 版 5.1 代码拆解 API 版和从零开始版本做的是同一个网络, 只是写法更短.
模型结构是:
1 2 3 4 5 6 net = nn.Sequential( nn.Flatten(), nn.Linear(784 , 256 ), nn.ReLU(), nn.Linear(256 , 10 ), )
对应结构是:
1 2 3 4 5 输入图片 [batch_size, 1, 28, 28] -> Flatten, 拉平成 [batch_size, 784] -> Linear(784, 256), 第一层全连接 -> ReLU, 非线性激活 -> Linear(256, 10), 输出层
5.1.1 参数在哪里 API 版没有显式写 W1, b1, W2, b2, 但它们仍然存在.
它们被封装在两个 nn.Linear 里面:
1 2 nn.Linear(784, 256), 内部有 weight 和 bias nn.Linear(256, 10), 内部也有 weight 和 bias
所以 API 版不是没有参数, 而是参数由 PyTorch 模块统一管理.
5.1.2 参数初始化 1 2 3 4 def init_weights (module ): if isinstance (module, nn.Linear): nn.init.normal_(module.weight, mean=0.0 , std=0.01 ) nn.init.zeros_(module.bias)
net.apply(init_weights) 会遍历模型里的每一层, 如果发现是 nn.Linear, 就初始化它的权重和偏置.
5.1.3 损失函数和 softmax 1 loss = nn.CrossEntropyLoss()
API 版也没有把 softmax 放进 net, 因为 CrossEntropyLoss 内部已经处理 softmax 相关计算.
5.1.4 优化器 1 trainer = torch.optim.SGD(net.parameters(), lr=lr)
net.parameters() 会自动拿到所有可训练参数, 包括两个 Linear 层里的权重和偏置.
5.2 完整代码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 import torchfrom torch import nnfrom torch.utils.data import DataLoaderfrom torchvision import datasets, transformsbatch_size = 256 num_epochs = 10 lr = 0.1 fashion_mnist_labels = [ "t-shirt" , "trouser" , "pullover" , "dress" , "coat" , "sandal" , "shirt" , "sneaker" , "bag" , "ankle boot" , ] def load_data_fashion_mnist (batch_size ): """下载并加载 Fashion-MNIST 数据集.""" transform = transforms.ToTensor() train_dataset = datasets.FashionMNIST( root="./data" , train=True , transform=transform, download=True ) test_dataset = datasets.FashionMNIST( root="./data" , train=False , transform=transform, download=True ) train_iter = DataLoader(train_dataset, batch_size=batch_size, shuffle=True ) test_iter = DataLoader(test_dataset, batch_size=batch_size, shuffle=False ) return train_iter, test_iter def init_weights (module ): """初始化线性层权重, 尽量和从零实现保持一致.""" if isinstance (module, nn.Linear): nn.init.normal_(module.weight, mean=0.0 , std=0.01 ) nn.init.zeros_(module.bias) def accuracy (y_hat, y ): """计算这一批图片里预测正确的数量.""" if len (y_hat.shape) > 1 and y_hat.shape[1 ] > 1 : y_hat = y_hat.argmax(axis=1 ) cmp = y_hat.type (y.dtype) == y return float (cmp.type (y.dtype).sum ()) class Accumulator : """简单累加器, 用来累计损失, 正确数量, 样本数量.""" def __init__ (self, n ): self .data = [0.0 ] * n def add (self, *args ): self .data = [a + float (b) for a, b in zip (self .data, args)] def __getitem__ (self, idx ): return self .data[idx] def evaluate_accuracy (net, data_iter ): """在测试集上计算准确率.""" net.eval () metric = Accumulator(2 ) with torch.no_grad(): for X, y in data_iter: metric.add(accuracy(net(X), y), y.numel()) return metric[0 ] / metric[1 ] def train_epoch (net, train_iter, loss, trainer ): """训练一轮.""" net.train() metric = Accumulator(3 ) for X, y in train_iter: y_hat = net(X) l = loss(y_hat, y) trainer.zero_grad() l.backward() trainer.step() metric.add(float (l.detach()) * y.numel(), accuracy(y_hat, y), y.numel()) train_loss = metric[0 ] / metric[2 ] train_acc = metric[1 ] / metric[2 ] return train_loss, train_acc def train (net, train_iter, test_iter, loss, trainer, epochs ): """训练多轮, 并打印每轮的训练损失, 训练准确率, 测试准确率.""" for epoch in range (epochs): train_loss, train_acc = train_epoch(net, train_iter, loss, trainer) test_acc = evaluate_accuracy(net, test_iter) print ( f"epoch {epoch + 1 :02d} : " f"train_loss={train_loss:.4 f} , " f"train_acc={train_acc:.4 f} , " f"test_acc={test_acc:.4 f} " ) def predict (net, test_iter, n=6 ): """训练结束后, 拿几张测试图片看看真实标签和预测标签.""" net.eval () for X, y in test_iter: break with torch.no_grad(): preds = net(X).argmax(axis=1 ) trues = [fashion_mnist_labels[int (i)] for i in y] preds = [fashion_mnist_labels[int (i)] for i in preds] print ("\n预测示例:" ) for i in range (n): print (f"{i + 1 } . 真实: {trues[i]:10s} 预测: {preds[i]} " ) if __name__ == "__main__" : torch.manual_seed(0 ) print ("加载 Fashion-MNIST 数据集..." ) train_iter, test_iter = load_data_fashion_mnist(batch_size) print ("创建 MLP 模型..." ) net = nn.Sequential( nn.Flatten(), nn.Linear(784 , 256 ), nn.ReLU(), nn.Linear(256 , 10 ), ) net.apply(init_weights) loss = nn.CrossEntropyLoss() trainer = torch.optim.SGD(net.parameters(), lr=lr) print ("开始训练..." ) train(net, train_iter, test_iter, loss, trainer, num_epochs) predict(net, test_iter)
代码运行.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 加载 Fashion-MNIST 数据集... 创建 MLP 模型... 开始训练... epoch 01: train_loss=1.0485, train_acc=0.6450, test_acc=0.6858 epoch 02: train_loss=0.6001, train_acc=0.7892, test_acc=0.7495 epoch 03: train_loss=0.5188, train_acc=0.8184, test_acc=0.8106 epoch 04: train_loss=0.4786, train_acc=0.8325, test_acc=0.8120 epoch 05: train_loss=0.4525, train_acc=0.8417, test_acc=0.8327 epoch 06: train_loss=0.4348, train_acc=0.8471, test_acc=0.8213 epoch 07: train_loss=0.4221, train_acc=0.8511, test_acc=0.8335 epoch 08: train_loss=0.4065, train_acc=0.8567, test_acc=0.8440 epoch 09: train_loss=0.3946, train_acc=0.8600, test_acc=0.8345 epoch 10: train_loss=0.3857, train_acc=0.8641, test_acc=0.8500 预测示例: 1. 真实: ankle boot 预测: ankle boot 2. 真实: pullover 预测: pullover 3. 真实: trouser 预测: trouser 4. 真实: trouser 预测: trouser 5. 真实: shirt 预测: shirt 6. 真实: trouser 预测: trouser